开云(中国) 台积电领先10年?黄仁勋误读了华为韬定律

文/不雅察者网 吕栋
“韬定律”火到了中国台湾。
5月28日,英伟达CEO黄仁勋在中国台湾台北的一场宴请供应链伙伴的晚宴后采纳媒体采访。当被问及对华为半导体“韬(τ)定律”和“逻辑折叠”工夫的见解时,黄仁勋给出了一个颇为走马看花的评价:“这对华为来说是冲破,但对台积电并不是恫吓。”
他合计台积电使用芯片堆叠和3D封装工夫仍是快10年,台积电的工夫绝顶先进,“华为使用这种工夫,不错在不将半导体制程线宽变得更细的情况下,把晶体管数目加倍,致使加多3到4倍,这是一种绝顶好的工夫,但台积电和台湾领有这项工夫仍是10年。”
这一评价听起来公允,实则建立在一个根人性的诬陷之上。黄仁勋把华为的逻辑折叠当成了台积电栽植了近十年的3D封装工夫的同类物。他想说的是“你们作念的那些东西,台积电十年前就仍是作念了”。但问题是,逻辑折叠和传统3D封装,压根不是一个东西。

台媒截图
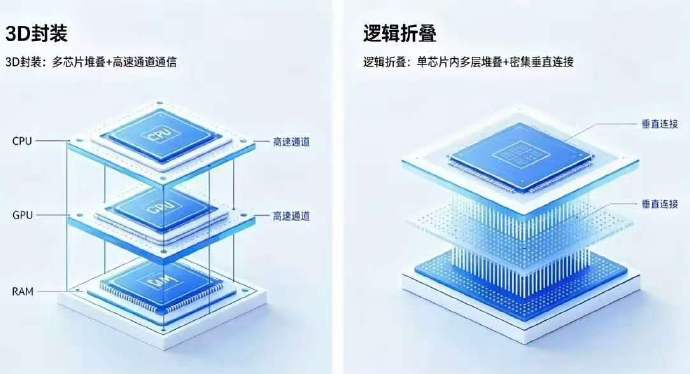
先望望华为到底作念了什么。逻辑折叠是华为韬定律的一项中枢工夫,它将正本平铺在二维平面上的电路,通过三维立体折叠和垂直互连“堆叠”起来,使要路门路走线长度镌汰50%到80%,大幅指责了信号传播的RC负载。
但这听起来似乎便是“把芯片堆起来”?事实远非如斯。
两者的中枢区别在于一个绝顶践诺的层面:2.5D/3D封装的中枢是运动仍是成型的幽静裸芯(die),而逻辑折叠的中枢是从头布局单颗裸芯里面的逻辑门。用更直白的话来说,前者是在制造后期尽可能让不同芯片贴得更近,后者则是在筹算图纸阶段就从压根上镌汰了信号的物理传输距离。逻辑折叠改动的是“信号自己要走多远”,而2.5D/3D封装改动的只是“不同芯片之间靠多近”。
博亚体育中国官网在线入口这意味着什么?意味着逻辑折叠践诺上是芯片筹算层面的电路拓扑重构,作用于单颗芯片里面逻辑层的纵向整合;而先进封装属于制造工艺层面的多芯片互联工夫。二者处于绝对不同的工夫概括层级,科罚的是不同维度的问题。
打个比喻就更好建壮了。传统的2.5D封装就像把两个幽静的房间搬到兼并层楼,中间修一条走廊(硅中介层)让它们不错相互来去。3D封装更进一步,就像把两栋幽静的楼叠起来,中间装几部电梯(TSV硅通孔),浅近楼上楼下串门。
但无论怎么作念,HBM和GPU践诺上仍然是两栋幽静的楼、两个物理上绝对分离的芯片。
而逻辑折叠呢?它是在筹算一栋大楼里面的房间布局时,就把正本应该放在东西两头且需要每每通讯的两个房间,成功一个放在一楼、一个放在它的正上方,中间无须走廊、无须电梯井,只在楼板上打一个极其短小的垂纵贯谈(间距仅1.5微米的极短TSV),两个东谈主探个头就能对喊。这是“筹算理念”的区别,不是“施工时势”的区别。
北京大学集成电路学院的一篇著作把这个区别讲得更彻底。著作淡薄了“真3D”与“赝3D”的范式分歧:赝3D以统统这个词模块为最小单元被分到某一派die,2026美加墨世界杯中国认证平台模块里面的统统圭臬单元势必位于兼并派die;真3D则复旧模块内开脱分歧,兼并模块内的圭臬单元不错被踱步到不同die,筹算空间更大。在优化空间上,赝3D在每片die上各自进行优化,大量复用传统2D芯片的EDA用具,不允许跨die逻辑变换、转移等操作;真3D则将多die构建的全体空间行动筹算空间,各筹算阶段均在齐备的三维筹算空间中进行搜索和寻优,不甘休跨die逻辑变换、转移等操作。


逻辑折叠把物理已毕的最小单元从“die”鼓励到了“圭臬单元在三维空间中的位置”。这才是着实的底层范式飘荡。台积电的CoWoS、SoIC等先进封装工夫天然优秀,但它们的使命对象是多颗幽静制造的die;逻辑折叠的使命对象是兼并颗die里面的组合逻辑门。一个是“把作念好的积木搭得紧凑一些”,一个是“在筹算积木体式时就接头怎么让它我方站得更稳”。
这少许黄仁勋似乎并莫得防御到。他把逻辑折叠归类为“芯片堆叠和3D封装工夫”,说他“台积电十年前就有了”,这个判断自己就把华为的工夫和台积电的代工智力拉到了兼并个赛谈上进行比较,然后说“敌手跑得没我快”。
可问题在于,这压根不是兼并条赛谈。
再看另一个层面的互异:先进封装的性能上风,必须与先进制程深度绑定才能绝对长远。举例台积电的CoWoS封装便是与N2 2nm制程配套筹算的,两者缺一王人会导致收益大幅缩水。而华为逻辑折叠的中枢冲破碰巧在于,在绝对不大幅改动现存制程节点的前提下,开云体育仅通过筹算层面的创新,就已毕了单代55%的晶体管密度汲引。这一跳跃,在传统摩尔定律的演进旅途下,需要整整两个制程节点的迭代才能完成,耗时爽气3年。
华为麒麟2026芯片便是最佳的讲明。比拟麒麟9030 Pro,麒麟2026的晶体管密度大幅汲引了53.5%,达到了238MTr/广宽毫米,这意味着每广宽毫米的芯单方面积上不错集成2.38亿个晶体管,表面上与Intel 18A工艺捏平,接近初代台积电3nm。同期,SoC性能核能效汲引41%,最高主频汲引近13%。这些数字不是靠松开线宽、更换制程得来的,而是在筹算端硬生生“挤”出来的。
更迫切的是,这只是是驱动。何庭波在演斗殴论文中给出了了了的阶梯图:从2026年到2031年,沿着韬定律旅途,晶体管密度将捏续汲引,瞻望2031年将冲破400MTr/mm²,CPU大核频率将冲破5GHz。
到当时,基于韬定律的高端芯片晶体管密度办法,将达到1.4纳米芯片制程的同等水平。也便是说,一条不依赖EUV、不依赖几何缩微的工夫旅途,不错在5年内追平面前起原进制程的性能水平。台积电是不是领先10年?要是看的是“筹算理念”这条新赛谈,谜底就怕并不那么细目。
天然,这条路并不好走。韬定律要着实落地,需要的远不啻芯片筹算厂商一家的努力。何庭波在论文中说得绝顶坦直:“大量怒放问题,无单一组织可幽静科罚——用具链、圭臬、基准、器件物理、经济模子均需跨界合作。”
逻辑折叠暗示
其中最难啃的骨头便是EDA用具链。传统的2D筹算历程乃至现行的“赝3D”筹算历程,已不及以承载逻辑折叠的后劲。要着实已毕逻辑折叠,物理筹算必须在齐备的三维空间中搜索,模块内分歧、跨die互连与垂直热旅途优化要在兼并个优化框架下协同求解。
好音信是,北京大学集成电路学院仍是在这方面获得了要道进展。该学院构建了面向逻辑折叠的“真3D”物理已毕EDA用具原型,笼罩布局计较和布局两个阶段,并通过GPU加快复旧千万级实例规模。比拟面前最具代表性的赝3D筹算历程,该用具获得了平均约30%的线长缩减和彰着的时序改善,在热感知方面启用荟萃优化后峰值温度平均着落3%以上。
韬定律的念念想内核,践诺上是一场从“几何念念维”到“系统念念维”的范式改进。何庭波的论文揭示了四个层级的τ:晶体管层的皮秒级、电路层的纳秒级、芯片层的微秒级、系统/数据中心的秒级。韬定律的中枢是把统统东谈主拉到兼并个账本前,全部用时候单元来算账。工艺巨匠省下的5皮秒,和架构师、软件巨匠省下的5皮秒,在总账本里的权重一模雷同。曩昔作念代工的只管把晶体管作念小,画电路图的只管布线,作念软件系统的只管写代码,人人讲话欠亨。面前τ定律强行买通了这些层级之间的壁垒。
这恰正是中国半导体产业需要的底层念念想转型。黄仁勋的误读,折射出的是一个更世俗的理解偏差:在摩尔定律的旧范式下浸润了太久,好多东谈主仍是民风了用“几何尺寸”“封装时势”来评判一切。但韬定律给出的谜底是,换一把尺子。
当几何尺寸的红利走到终点,率先进制程的老本飙升到难以承受,华为淡薄的是一条用“系统工程的整合智力”去对冲“单体芯片的工艺短板”的谈路。以时空换几何,以系统赢单点。这不是在台积电的赛谈上试图稀奇台积电,而是费力于“换谈超车”。
黄仁勋说“台积电领先10年”开云(中国),没错,要是只看3D封装这种制造工艺层面的话。但逻辑折叠压根不是3D封装,它是一项筹算理念层面的革新。把两件处于绝对不同概括层级的工夫放在沿途比较,然后断言谁领先谁10年,这自己便是一个界限伪善。好像说得更成功少许:黄仁勋就怕并莫得持重读何庭波的那篇论文。